Git 与 Gerrit
为什么需要版本控制系统,我想点进这篇文章的读者应该都已经对这个问题了然于胸,所以不再废话。
我们会从版本是控制系统的历史发展开始着眼,到分布式系统仓库的概念,以及从仓库之间的数据传输协议,到最后的仓库的权限控制系统 Gerrit 一一讲过,来理解这些系统的使用方式和设计理念。
分布式 Git
我们都听过 Git 是完全分布式的,那么所谓的分布式怎么理解呢?
要理解 Git 的的分布式,就需要来看一下版本控制系统的发展历程,从发展中看事物产生的必然性
本地版本控制系统
在互联网还未出来或者还在萌芽的时候,版本控制系统大多以本地为主,因为没有太多协作的必要性,软件规模也不是很大,所以版本控制系统还比较简单。
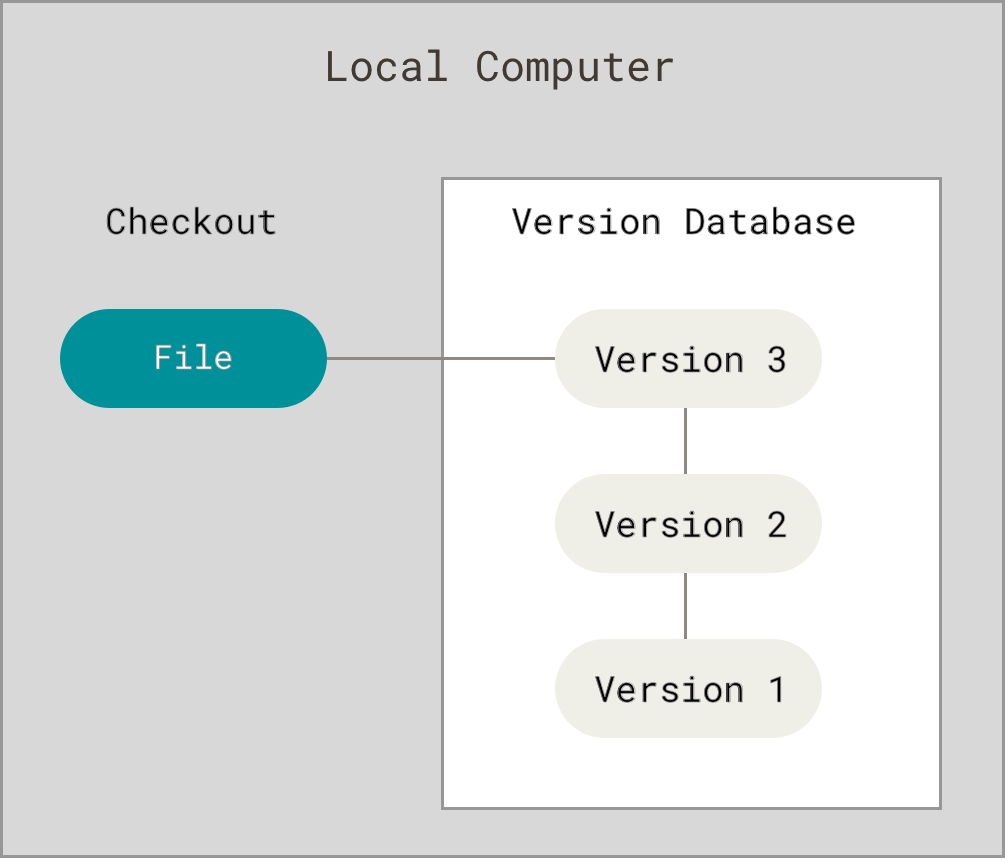
本地代码控制系统优缺点明显:
简单的版本控制,数据容易丢失,无法和其他人协作,但胜在简单,有简单的数据库管理版本历史
集中式版本控制系统
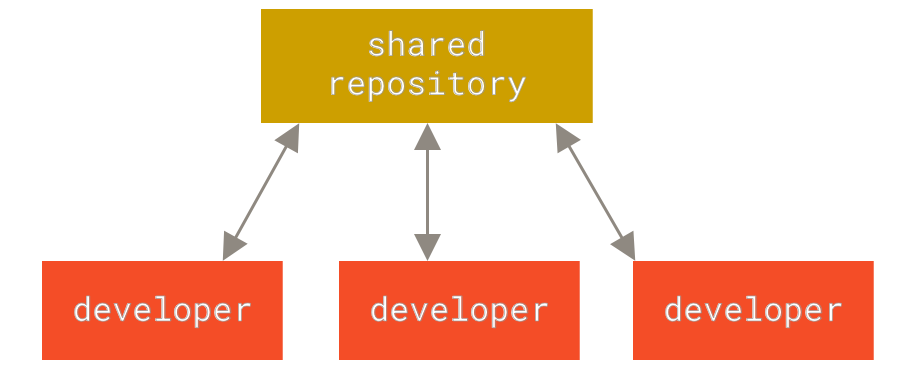
为了应对多人远程协作而发展出来的版本控制系统,以版本控制服务器为中心提供代码仓库,多个开发人员和服务器交互,服务器针对开发人员开放版本快照,而且强依赖网络,如果没有好的备份策略,无法很好地应对数据丢失的问题
分布式版本控制系统
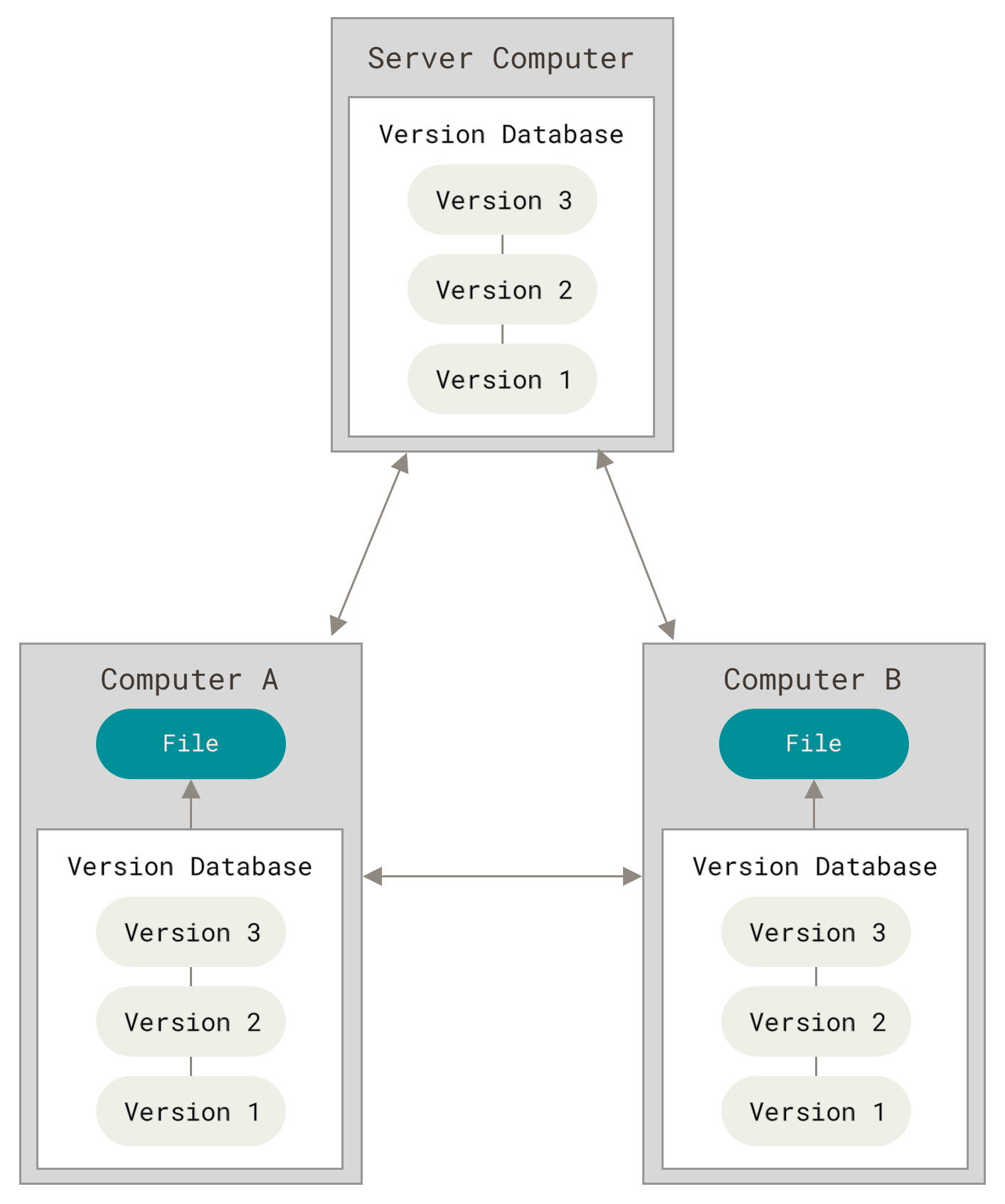
不同于集中式版本控制系统,分布式版本控制系统的每台主机都可以成为服务器,他们之间是对等的关系,对应的上边的示意图中,Computer A 和 Computer B 不需要 Server 也可以交换数据,交互数据使用统一的协议,这协议有我们熟悉的 HTTP 协议,也有相对陌生的 SSH 协议,还有 Git 基于 SSH 封装过的 Git 协议,每个协议都有自己擅长的方向,我们在后边会细细讲到。
从另一方面来说,分布式的这种概念,就是每台主机都包含全部的历史记录,这样可以避免我们上边讲到的集中式版本控制系统的两个缺陷,数据备份和离线开发。当服务器代码丢失之后,可以从任何一个开发人员的本地仓库中恢复,“鸡蛋” 不会放到一个篮子里。
注意:各个 Git 仓库之间同步的是一种叫做”元数据“的内容,属于 Git 版本控制系统中的数据库内容,不涉及直接操作原始的项目代码
既然在分布式下,每个仓库都是平等的,都可以提供源代码,那么 Git 是如何区分每个仓库呢?又如何在不同的仓库之间传输信息呢?
Git Remote
在 Git 中,我们通过 remote 这个关键字标识想要与之同步的其他仓库,每个 remote 都由 name 和 url 组成
- name 表示仓库的名称,方便后续引用,也方便区分多个不同的仓库
- url 表示仓库的地址,标识了这个仓库唯一性,后续具体数据同步实际都是通过这个地址来进行
我们可以通过 git remote 指令来获取这部分信息
1 | $ git remote -v |
以上示例是 glide 在 Github 上的仓库 clone 到本地,我们可以看到有一个名称为 origin 的远程仓库,协议为 https,后边括号中说明了当前地址是被用来 fetch 还是 push,我们也可以据此推出 fetch 和 push 支持分别指定不同的地址
注:origin 是 git 默认指派的 remote 名字,我们可以通过
git remote rename origin xxxx换成自己喜欢的名字
我们在这个工程下增加追踪一个使用 ssh 协议的远程仓库,如下:
1 | $ git remote add back ssh://gitlab.com/bumptech/glide_back.git |
增加完成这个仓库,我们就可以使用 fetch 和 push 来分别从 back 这个远程仓库拉取和推送代码,如果完全去中心化,那么对于多人协作来说,每个人都可以通过这样的方式处理多个远程仓库的代码合并,完成协作。
接下来我们来详细了解每台主机之间是如何通信的,也就是 Git 的通信协议。
传输协议(HTTP or SSH)
Git 使用四种主要的协议来传输资料:本地协议(Local),HTTP 协议,SSH(Secure Shell)协议及 Git 协议。
可以看到 Git 其实并没有自己创建新的协议信息,而是使用了已有的互联网主流的传输协议,避免了重复造轮子,也降低了使用成本。
本地协议只适用与本地备份,Git 协议缺少授权机制和加密机制,使用成本较高,所以我们这里只来简单看两个最常见的协议: HTTP 协议 和 SSH(Secure Shell)协议
HTTP
Git 通过 HTTP 通信有两种模式。 在 Git 1.6.6 版本之前只有一个方式可用,十分简单并且通常是只读模式的。 Git 1.6.6 版本引入了一种新的、更智能的协议,让 Git 可以像通过 SSH 那样智能的协商和传输数据。
HTTP 协议因为其广泛的使用,所以大多数的防火墙都不会禁止 HTTP/S 的端口,所以使用较为方便
另外一个好处时,可以直接通过 HTTP 的授权来使用 Git 仓库,方便快捷。
但缺点同样明显,HTTP 每次推送改动都会需要校验用户名和密码,虽然各个平台有管理认证凭证的工具,但是用起来相对复杂
SSH
SSH 协议的优缺点也是简单明显:
- 通过 SSH 访问是安全的 —— 所有传输数据都要经过授权和加密。
- 但是 SSH 协议无法匿名
通常,我们在 clone 代码的时候,服务器会提供给我们可选的协议,作为项目的主要开发者,我们日常使用的都是 SSH 协议,因为免去了每次都要认证的烦恼,而且也很高效,而对于很多公开代码的仓库来说,因为 HTTP 支持匿名访问,所以大多都使用 HTTP 协议提供下载。
解决完对仓库的权限认证之后,我们还有一个问题需要处理:代码合入权限
Gerrit
如果你之前用过 github 或者自己搭建过版本控制服务器,你就会发现,我们之前的代码都是直接推送到仓库中的,并没有经过审核,这对于个人开发者或者小团队来说,效率很高,但是对于大的项目来说,代码审核是控制版本质量,控制代码质量必须有的一步。Git 自身其实没有提供代码审查的功能,任何的改动,只要有权限,都是可以直接操作源码仓库的,对仓库的权限力度来说,要么有合入权限,要么没有合入权限,这对于团队开发来说是不合理的。
所以,基于代码审核的需求,gerrit 应用而生。
以下是 Git Server 和 Gerrit Server 的演进图


很明显的可以看到,gerrit 提供了一个开发者和代码仓库服务器之间的屏障,开发者是没有权限直接合并到代码服务器的版本控制系统的,只能推送到 gerrit 提供的一个叫做 “Pending Changes” 的区域,这个区域内的代码会交由 Reviewer (通常是团队的负责人)审核并合入。这种方式限定了开发者直接操作源码服务器的能力,而是经由代码审查之后合并到主分支,大大提升了项目质量和版本质量。
拓展:这个屏障是怎么做到的,
提示:通过 refs/for/xxx 的命名空间,每次 push 代码,都是类似于 git push origin HEAD:refs/for/master
通过 gerrit 这样的一个中转平台,就可以很大的扩展 git 的功能,综合来说,Gerrit 有以下的优点:
- 代码 review
- 历史合并记录查询
- 某个提交的流动记录查询
- 权限控制
- 可视化窗口管理
- 简易的代码编辑工具
- 知会相关开发者代码变动
- 和其他网站联动进行自动化
有些人会对第三点有疑问:什么是某个提交的流动记录?
这里就不得不提 Gerrit 创建出来的一个概念:Change-Id
多数人第一次见到这个词是比较懵的,因为在 git 的官方文档中并没有这个词的说明。没错,这个关键字 git 并不使用,也不会识别。真正用到它的是 gerrit,我们的代码审查服务器。
理解 Change-Id 之前,有一个容易混淆的概念我们一并讲一下,那就是 Commit-Id
Commit-Id
通常,我们会将一些工作内容的变更打包成一个 commit 对象,然后放到 Git 的数据库中存起来,打包的每个 commit 对象都带有一个 id,称之为 commit-Id,这个 id 唯一标示了本次打包这一操作,一旦因为重新打包或者移动了这个 commit 对象,那么 id 就会随之发生变化。
我们可以通过一下方式更改 commit-Id:
- 重新打包可以使用 git commit –amend,git rebase 修改历史提交,或者使用git reset 撤销再次提交做到重新打包
- 移动 commit 对象,可以用 git cherry-pick 或者 git rebase
- 使用git push 和 git pull/fetch 只是同步数据库并不会更改 commit 对象
那么 Change-Id 是用来做什么的呢?
Change-Id
Gerrit needs to identify commits that belong to the same review. For instance, when a change needs to be modified, a second commit can be uploaded to address the reported issues. Gerrit allows attaching those 2 commits to the same change, and relies upon a Change-Id line at the bottom of a commit message to do so. With this Change-Id, Gerrit can automatically associate a new version of a change back to its original review, even across cherry-picks and rebases.
以上官方内容,简单用一句话来说:为了识别一个提交的多次更改
什么情形下会用到这个呢,我们来想象这么一个场景:
我们提交一笔 Commit-Id 为 A 的提交到 Gerrit 服务器,然后突然想到需要追加一个文件,我们使用git commit --amend 追加到前一个提交,然后提交到 Gerrit 服务器,按照我们的预期,这应该是一笔提交,但是服务器确会出现两笔提交,因为追加的第二笔提交 Commit-Id 会被更改,所以会被认为这是两笔提交,解决这个问题的方法是引入 Change-Id 标示这两笔改动都属于一个 Change-Id,这样在推送前后两笔提交的时候,Gerrit 会关联两笔提交作为提交的不同版本,而不是不同的提交。
对于上文中提到的可以更改 Commit-id 的 cherry-pick 和 rebase 方式,Gerrit 也可以使用这种方式追踪,这也就是前文提到的 Gerrit 可以追踪同一个提交在不同分支的流动记录,就是通过 Change-id 方式实现的。
我们在 gerrit 网站上会看到 patch-set update 的提示,并且这多个 patch set 之间的变更记录也可以通过 diff 的方式追踪
在 gerrit 可以通过 change-id 来搜索同一个提交的不同分支的流动记录。
文章的最后,我们来讲一下为什么要使用命令行,而不是 GUI 工具。
为什么要使用命令行
- 所见即所得
GUI 工具大多呈现给我们的是他们想给我们呈现的,内部是黑盒的,而命令行工具,执行到哪一步,遇到什么错都可以一目了然。 - 你可以用在 GUI 工具中使用的命令,在命令行中都可以使用,反之则不然。
- 最重要的一点,你可以从命令行中获取帮助
1 | $ git remote -h |
写在最后
Git 和 Gerrit 一样,产生都有其历史必然性,Git 是在 “Linux 之父” Linus 在无法忍受集中式版本控制系统缺点的背景下被开发出来的,而 Gerrit 是 Google 为了合适的管理 Android 代码中来自世界成千上万开发者补丁合并而开发的权限控制系统,所以每个软件或者系统的开发都有其相应的背景,理解这些背景,可以让我们清晰的看到这些系统的设计者的用心良苦和深谋远虑,从而在认识或者使用这些系统或工具时,能够从更深的层次去看待问题。
欢迎关注我的公众号 0xforee,第一时间获取更多有价值的思考


